First off, always remember that garbage in = garbage out; so if your data is garbage then your statistics will be garbage.
In this situation your optimal data would be something like Run Hours Until Failure and your entire dataset would have failed already. With this in mind you may want to choose a conservative number from whatever statistic you calculate.
Since you only have failure from sale date this may be skewed toward a higher MTTF.
Since not all of your product has failed yet you can look at a smaller subset of your population, say the 1st six months of production. A higher percentage of these have failed most likely (since the product you sold last week shouldn't fail this week, hopefully).
If your failure proportion is still too low then you may have to try to fit the data to a distrubution keeping in mind that you only have the low proportion of the distribution, i.e. you must extrapolate from the dataset to a fitted curve.
For example, Weibull Distribution would work well here and is commonly used for MTTF data. The idea here is to fit the proportion of your dataset which has failed to a corresponding proportion of a distribution. If your proportion of products in your dataset which have failed was 48.66% then you would fit it to that probability on your hypothesized distribution as shown by the shaded area in the following image.
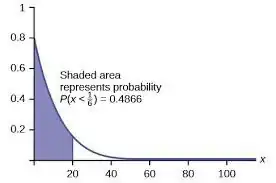
This can be rather intensive, however, for anything besides an exponential distribution.
Another method of extrapolation is by Degradation Analysis
